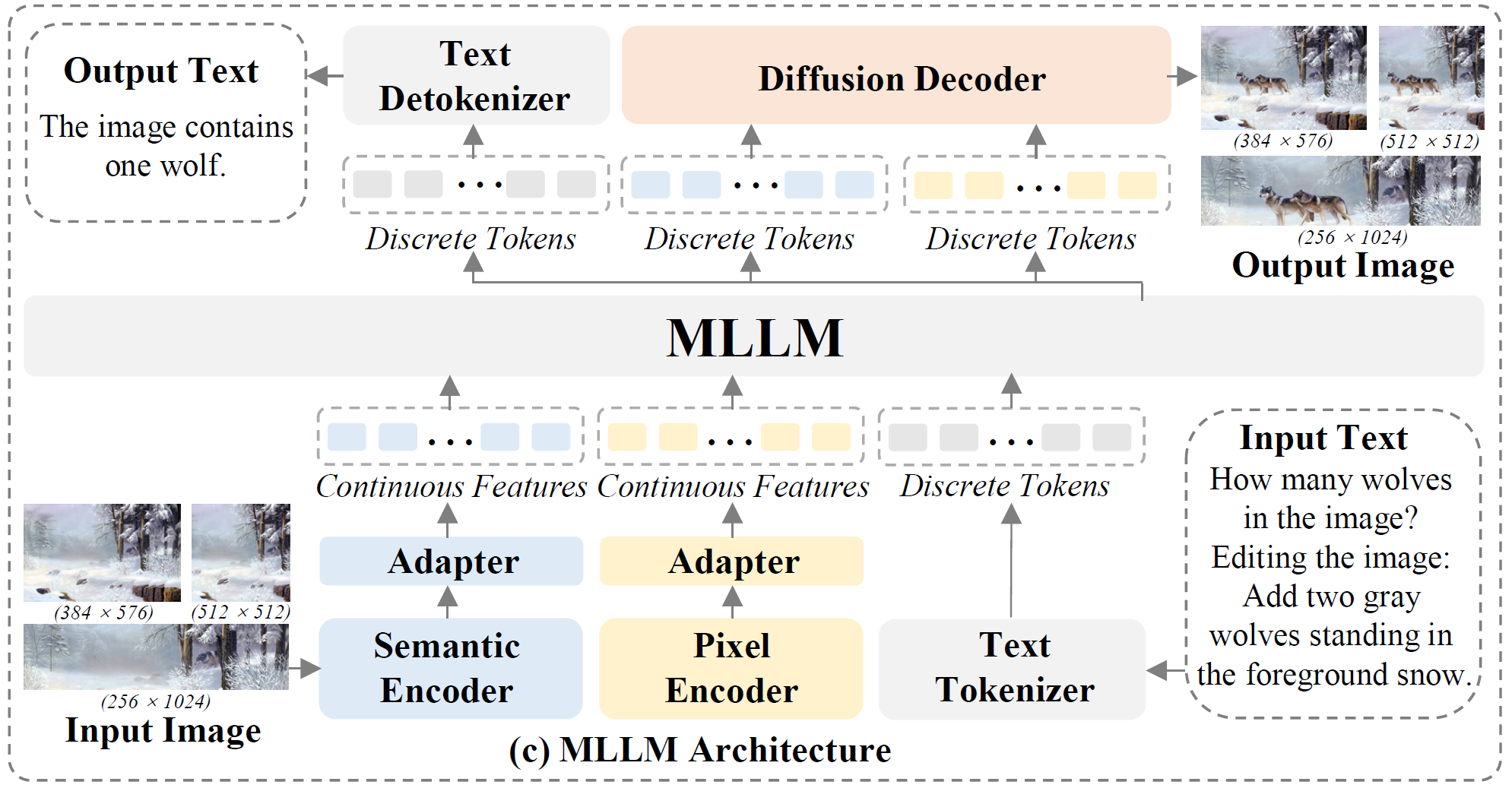
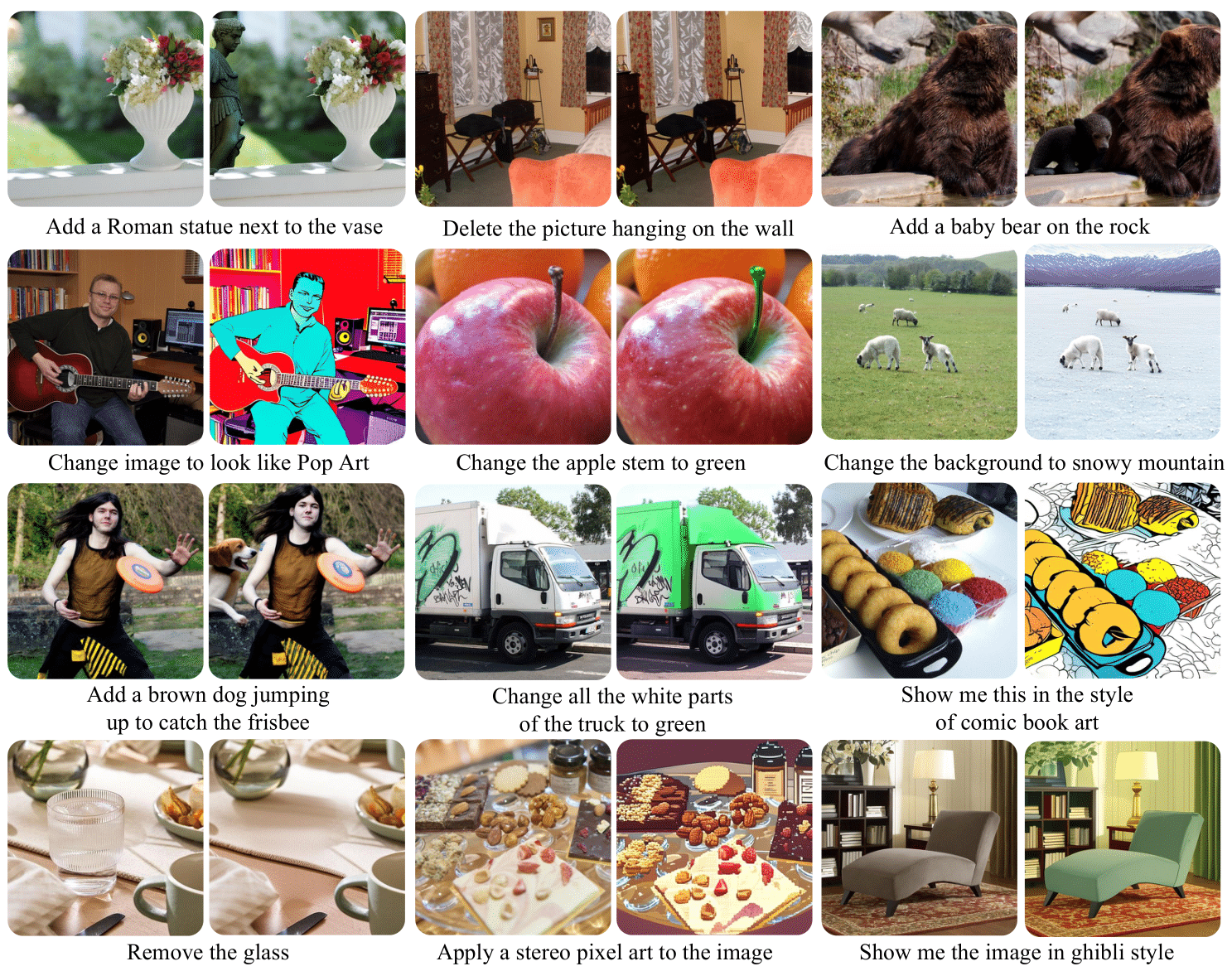
We present ILLUME+, an enhanced version of the previous ILLUME model, which leverages dual visual tokenization and a diffusion decoder to improve both deep semantic understanding and high-fidelity image generation. Existing unified models have struggled to simultaneously handle the three fundamental capabilities expected of a unified model: understanding, generation, and editing. Models like Chameleon and EMU3 utilize VQGAN for image discretization, due to the lack of deep semantic interaction, they lag behind specialist models like LLaVA in visual understanding tasks. To mitigate this, LaViT and ILLUME employ semantic encoders for tokenization, but they struggle with image editing due to poor texture preservation. Meanwhile, Janus series decouples the input and output image representation, limiting their abilities to seamlessly handle interleaved image-text understanding and generation. In contrast, ILLUME+ introduces a unified dual visual tokenizer, DualViTok, which preserves both fine-grained textures and text-aligned semantics while enabling a coarse-to-fine image representation strategy for multimodal understanding and generation. Additionally, we employ a diffusion model as the image detokenizer for enhanced generation quality and efficient super- resolution. ILLUME+ follows a continuous-input, discrete-output scheme within the unified Multimodal Large Language Model (MLLM) and adopts a progressive training procedure that supports dynamic resolution across the vision tokenizer, MLLM, and diffusion decoder. ILLUME+ (3B) exhibits competitive performance against existing unified MLLMs and specialized models across multimodal understanding, generation, and editing benchmarks. With its strong performance, ILLUME+ provides a scalable and versatile foundation for future multimodal applications.
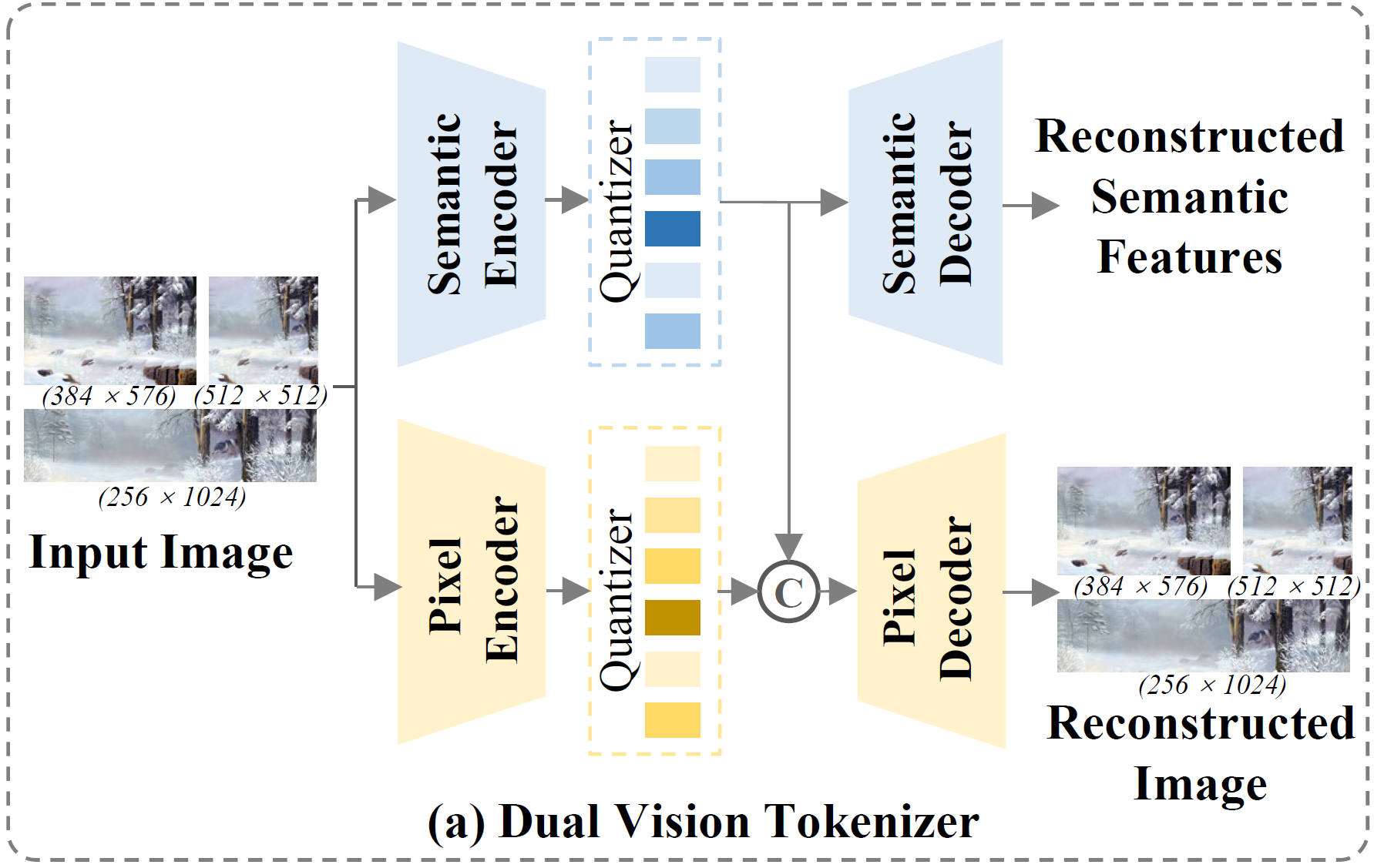
We introduce the Dual Vision Tokenizer (DualViTok), a dual-branch vision tokenizer designed to capture both deep semantics and fine-grained textures. The semantic branch utilizes a pre-trained text-aligned vision encoder for semantic feature extraction, supervised by feature reconstruction loss. In parallel, the pixel branch integrates quantized features from both the semantic encoder and a CNN-based pixel encoder to enhance pixel-level reconstruction. To improve robustness against incorrect token predictions in autoregressive generation, we introduce noise injection during training by randomly perturbing visual tokens. Despite its simplicity, DualViTok is specifically designed for unified models, ensuring both semantic and texture preservation while maintaining robust token decoding.
We adopt a coarse-to-fine strategy, first generating semantic tokens followed by pixel tokens. This sequential arrangement enables LLMs to utilize a unified LM head with a simple vocabulary expansion while leveraging semantic visual tokens as a bridge to enhance alignment between text and visual textures. Additionally, to prevent information loss at the input stage, we employ a continuous-input, discrete-output scheme following ILLUME, using pre-quantized continuous features as inputs while generating discrete tokens for image synthesis.
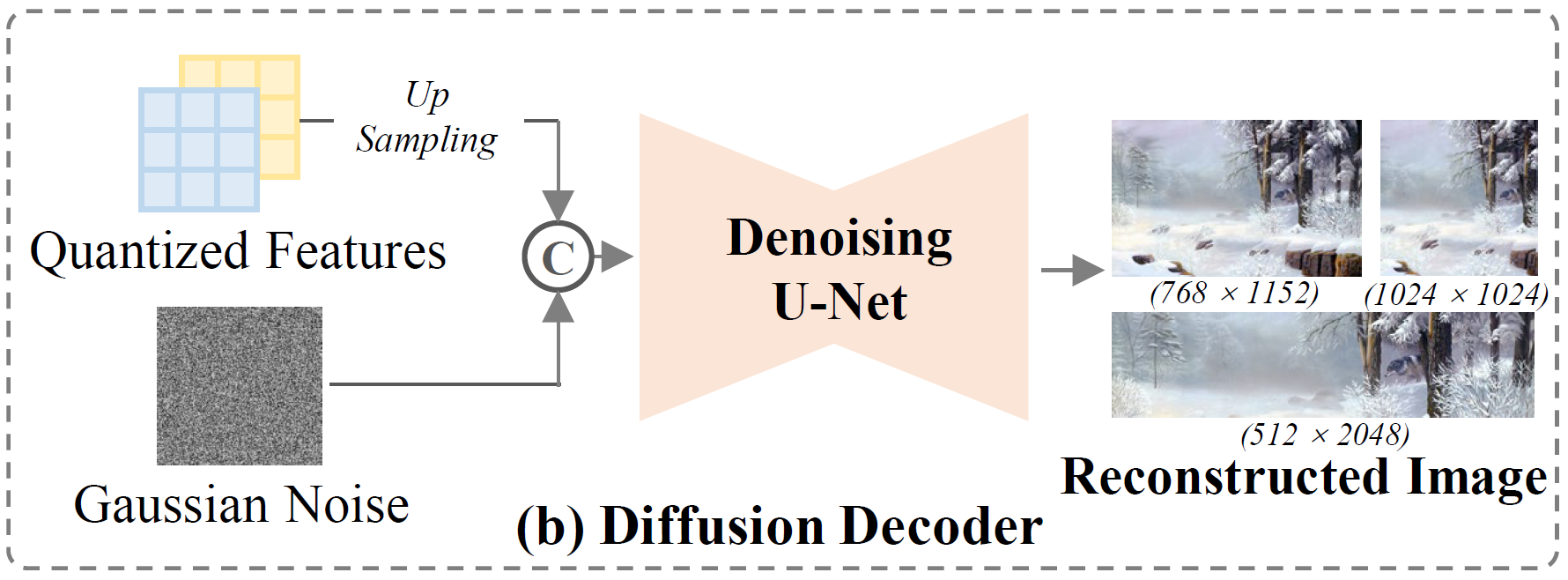
We incorporate a diffusion model as an optional choice for image generation, offering two key benefits: (i) Higher generation quality. Diffusion models refine details and reduce artifacts, surpassing direct token decoding from a vision tokenizer in both fidelity and robustness. (ii) Efficient super-resolution. They upscale images during decoding, mitigating the token explosion issue in autoregressive high-resolution generation.
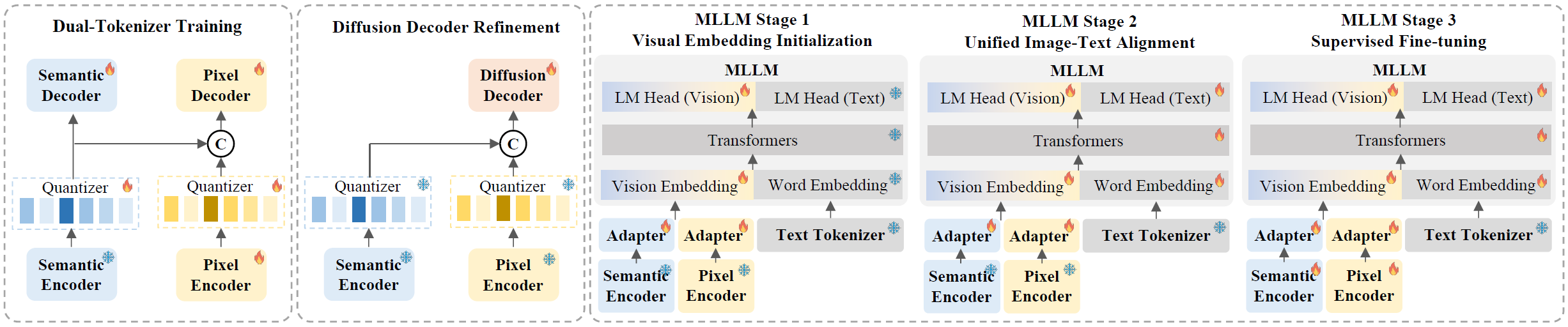
We employ a progressive training procedure for all the above three modules, gradually increasing resolution from fixed low to flexible high, to ensure training stability and final performance. Additionally, during MLLM training, we incrementally increase tasks diversity and complexity, with carefully designed data distribution for each stage.
@article{huang2025illume_plus,
title={ILLUME+: Illuminating Unified MLLM with Dual Visual Tokenization and Diffusion Refinement},
author={Huang, Runhui and Wang, Chunwei and Yang, Junwei and Lu, Guansong and Yuan, Yunlong and Han, Jianhua and Hou, Lu and Zhang, Wei and Hong, Lanqing and Zhao, Hengshuang and Xu, Hang}
journal={arXiv preprint arXiv:2504.01934},
year={2025}
}